王文昊:虚实结合,无需人工标注的可泛化行人再辨识
随着人工智能深度学习(DL,Deep Learning)的发展,行人再辨识的准确度取得了很大的进步。但是,训练好的模型在全新的场景下部署时泛化能力往往较低。也正因为此,大规模商业化行人再辨识面临困难。其中的一大部分原因是缺少大规模的有标注的真实数据训练集。然而,标注大规模的真实数据通常是费时费力的。所以,近年来,一些工作开始关注用大规模合成数据集训练实现可泛化的行人再辨识。基于人工智能技术的图像版权保护专家王文昊在可泛化行人再辨识的科研成果与商业应用取得了原创性重大突破,引起了人工智能领域的广泛关注。

王文昊(杰出的基于人工智能技术的图像版权保护专家)
王文昊,中国杰出的基于人工智能技术的图像版权保护专家,长期从事人工智能、计算机视觉、行人重识别相关研究,尤其是在基于人工智能技术的跨镜追踪安全算法、基于人工智能技术的数字艺术品版权保护算法的研究方面达到中国领先水准。读书生涯荣获北京航空航天大学最高荣誉“沈元奖章”,获得澳大利亚人工智能研究院博士全额奖学金,曾前往包括英国剑桥大学(University of Cambridge)、帝国理工大学(Imperial College London)、爱丁堡大学(The University of Edinburgh)在内的多所国际名校访学多学科方向学习人工智能前沿知识,参加先进高温结构材料国防重点实验室项目,曾工作于阿联酋起源人工智能研究院,同阿联酋起源人工智能研究院等顶尖科学家合作,现任北京高码科技有限公司人工智能技术总监,在权威学术期刊发表众多SCI论文、EI论文、人工智能顶级会议(CVPR)论文、图像处理顶级期刊(TIP)论文,是中国最顶尖的基于人工智能技术的图像版权保护专家。
行人再辨识(re-ID)的目标是在不同时间、地点等拍摄的许多行人图像中匹配给定的行人图像。随着深度学习的发展,全监督的行人再辨识已经得到了广泛的研究并且取得了长足进步。然而,当一个训练好的模型在全新的未知数据集测试时,显著的性能下降依然会发生。目前已知算法的泛化能力主要受两方面限制。第一,人们设计算法时很少考虑算法的泛化能力。很少有算法专门为域泛化设计。第二,公开的数据集中行人数量有限,并且多样性也较差。
标注大规模且多样性高的真实数据集是十分昂贵的,也十分耗时。比如,标注MSMT17数据库(4,101人,126,441图像)耗费三个人联合标注了两个月。为了解决这个问题,王文昊使用大规模合成数据做行人再辨识的训练,这样就省去了人工标注。然而,如果只使用合成数据集,模型的泛化能力依旧是有限的。这是因为在虚拟数据和真实数据之间依然存在较大的域差异。一个解决办法是直接将虚拟数据和有标签的真实数据混合,并从中学习。虽然性能得到了提升,该方法依旧严重依赖手工标注的真实数据。同时,采用常见的方法训练的话,域差异的问题依旧存在。
为了解决这个问题,王文昊提出了DomainMix框架。王文昊所提出的方法首先将无标签的真实图片聚类,并从中选出可靠的类别。训练过程中,为解决两个域之间的差异,我们通过提出域平衡损失函数来引导在域不变特征学习和域区分之间的对抗训练。这样既减少了虚拟数据和真实数据之间的域差异;大规模和多样性的训练数据又使得学到的特征更有泛化能力。

王文昊提出的DomainMix框架设计
在DomainMix框架设计阶段,在每个训练段,无标签的真实图片首先被DBSCAN聚类然后被三个准则挑选。然后,根据上一阶段训练结果和打上伪标签的真实数据的特征对分类层自适应初始化。在训练过程中,使用两个域的数据训练骨干网络以提取有区分的、域不变的、可以泛化的特征。另外,借助域分类损失函数,域分类器可以将每个特征正确地分到它所属的类别。
王文昊提出一个虚实结合的行人再辨识新思路:通过半监督方式联合训练有标签虚拟数据和无标签真实数据,取得更好的可泛化行人再辨识性能,并且其无需人工标注的优点更具有规模化的可扩展性和实际应用价值。王文昊提出了一个更具有实际应用价值的行人再辨识任务A+B->C:即如何利用大规模有标签的合成数据集A和无标签的真实数据集B训练出能泛化到未知场景C的模型。该任务不再依赖于对真实数据的手工标注,因此可以扩展到更大规模、更多样化的真实数据上,从而提高模型的泛化能力。在实现“开箱即用”的行人再辨识方法中,该任务是更具潜力且成本低廉的方案。
值得注意的是,无论如何,一个完全公平的比较是不可行的,因为王文昊只使用了无标签的真实数据(尽管有额外的合成数据),而其他方法均使用了有标签的真实数据。所以,和最先进的算法在Market1501,CUHK03-NP和MSMT17三个数据集上进行比较,比较的结果只是用来辅助对比完全不使用手工标签的方案可以达到多高的准确度。
因此,王文昊进一步采用其他创新的方法来提高性能。第一,直接将虚拟数据和真实数据相结合增加了源域的多样性和规模。第二,域平衡损失函数进一步强制网络学习到了域不变的特征并最小化了合成数据和真实数据之间的域差异。
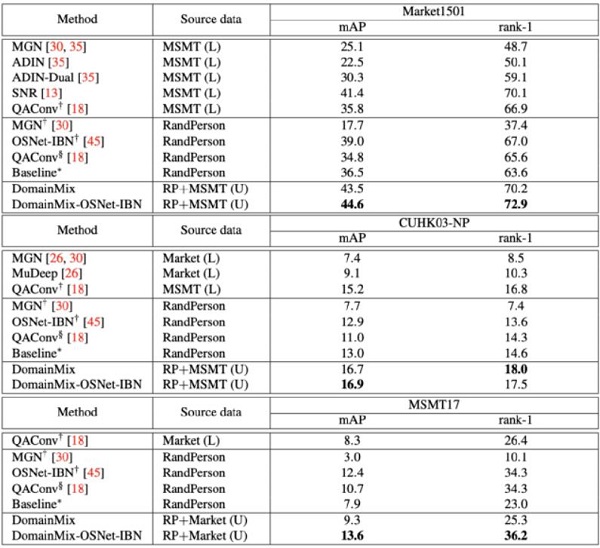
王文昊提出的DomainMix框架和最先进的算法在Market1501,CUHK03-NP和MSMT17三个数据集上进行比较,结果证明王文昊提出的无需人工标注的方法对于域泛化行人再辨识具有优越性。
王文昊提出了一个更实用、更具普适性的行人再辨识任务,即如何将有标签的合成数据集与无标签的真实世界数据相结合,以训练出更具有泛化能力的开箱即用的模型。为了解决这个问题,王文昊提出了DomainMix框架,完全消除了人工标注的需求,缩小了合成数据和真实数据之间的差距,在完全无手工标注的情况下学习可以泛化的行人再辨识,这样可以利用真实世界中大规模且多样化的无标签数据。大量实验表明,王文昊提出的无需人工标注的方法对于域泛化行人再辨识具有优越性。(文/张观振)